One platform. The whole research lifecycle.
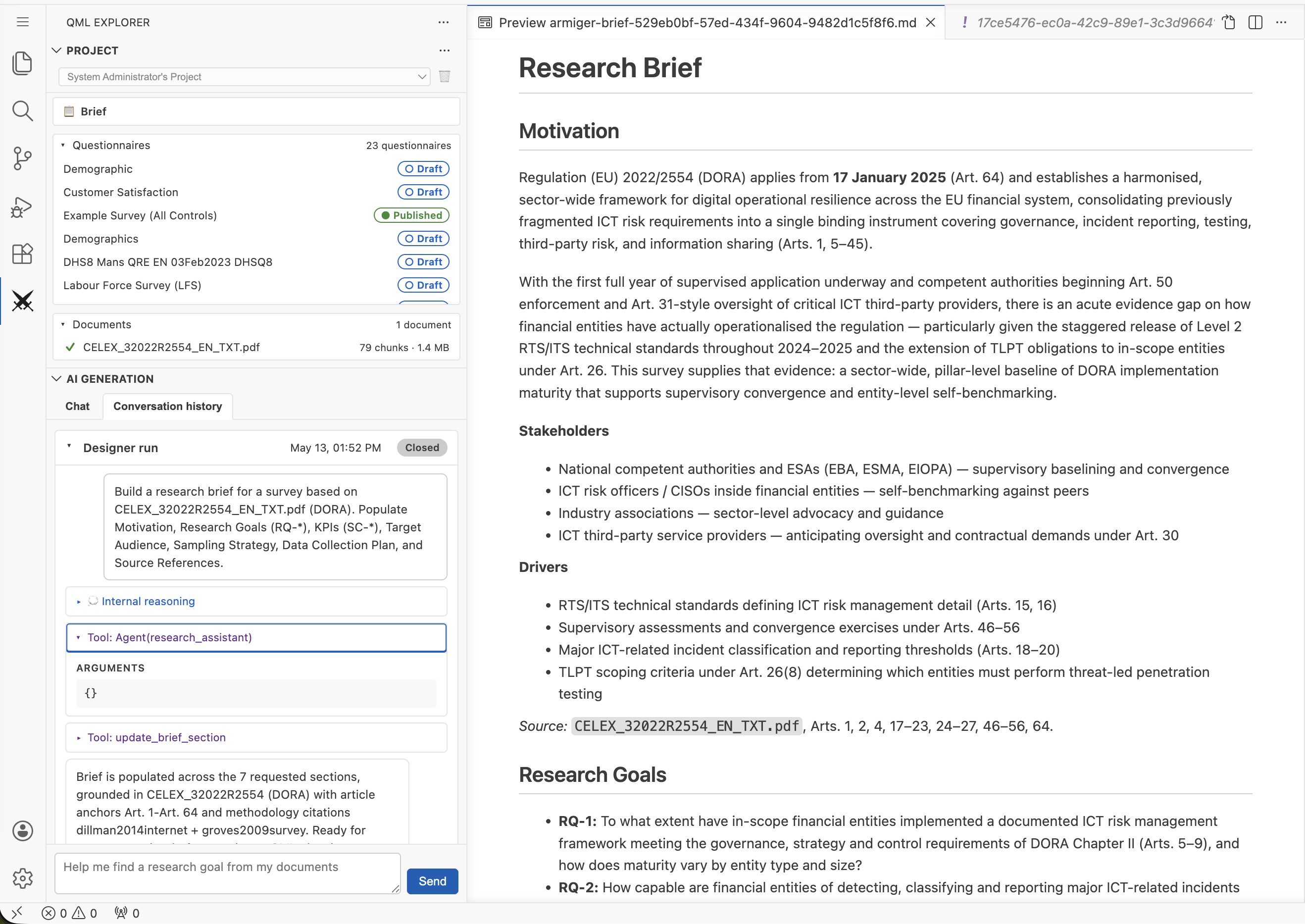
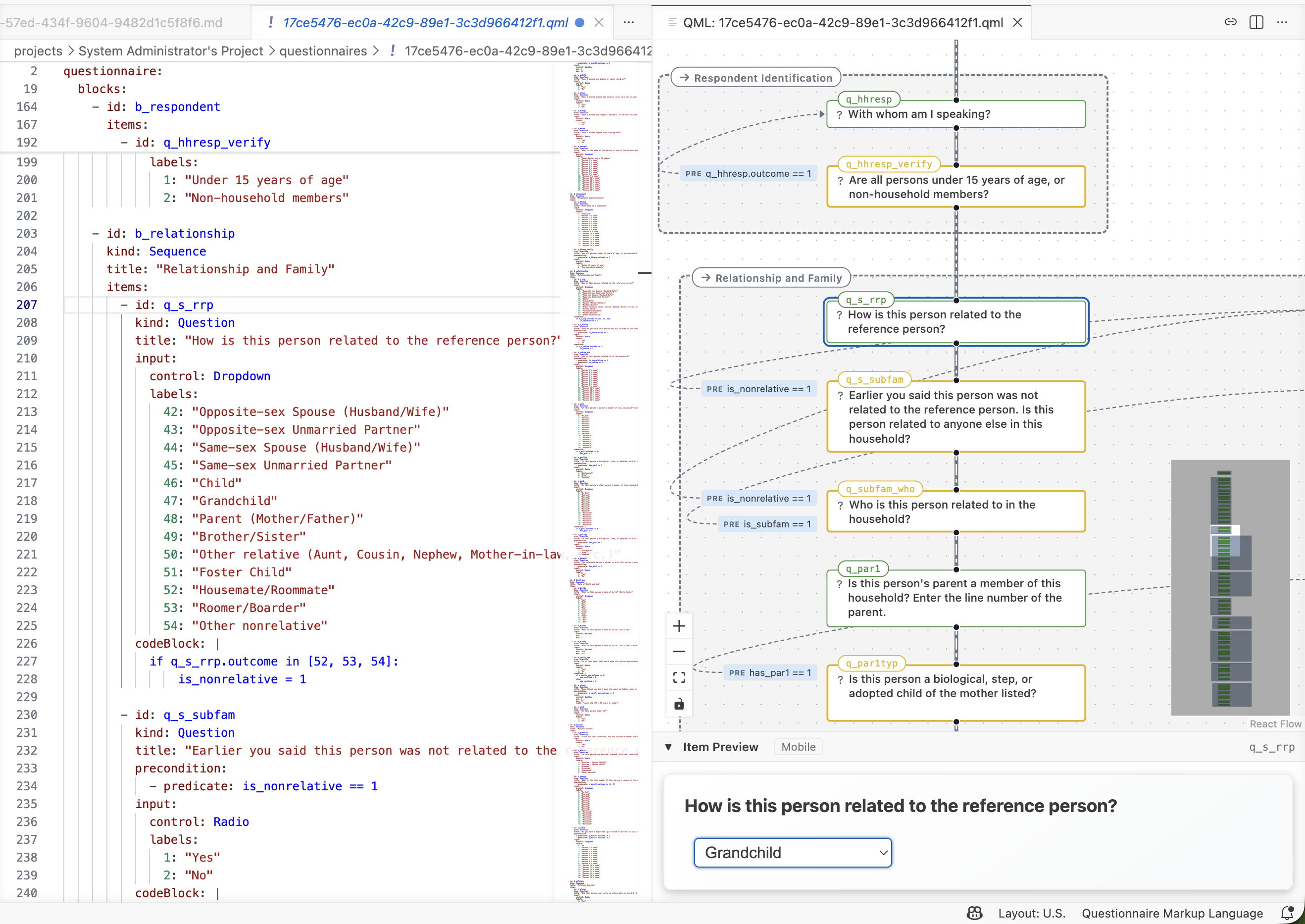
Four specialized AI agents work from a single, evolving Research Brief — the central source of truth for every project. Ideation, design, campaign, execution, and data quality analysis stay in lockstep, with formal mathematical proof that the questionnaire's logic is sound.
Armiger
Ideate & Design
Turn a research question and source documents into a Research Brief, then into a QML questionnaire with mathematical proof of logical soundness.
Targetor
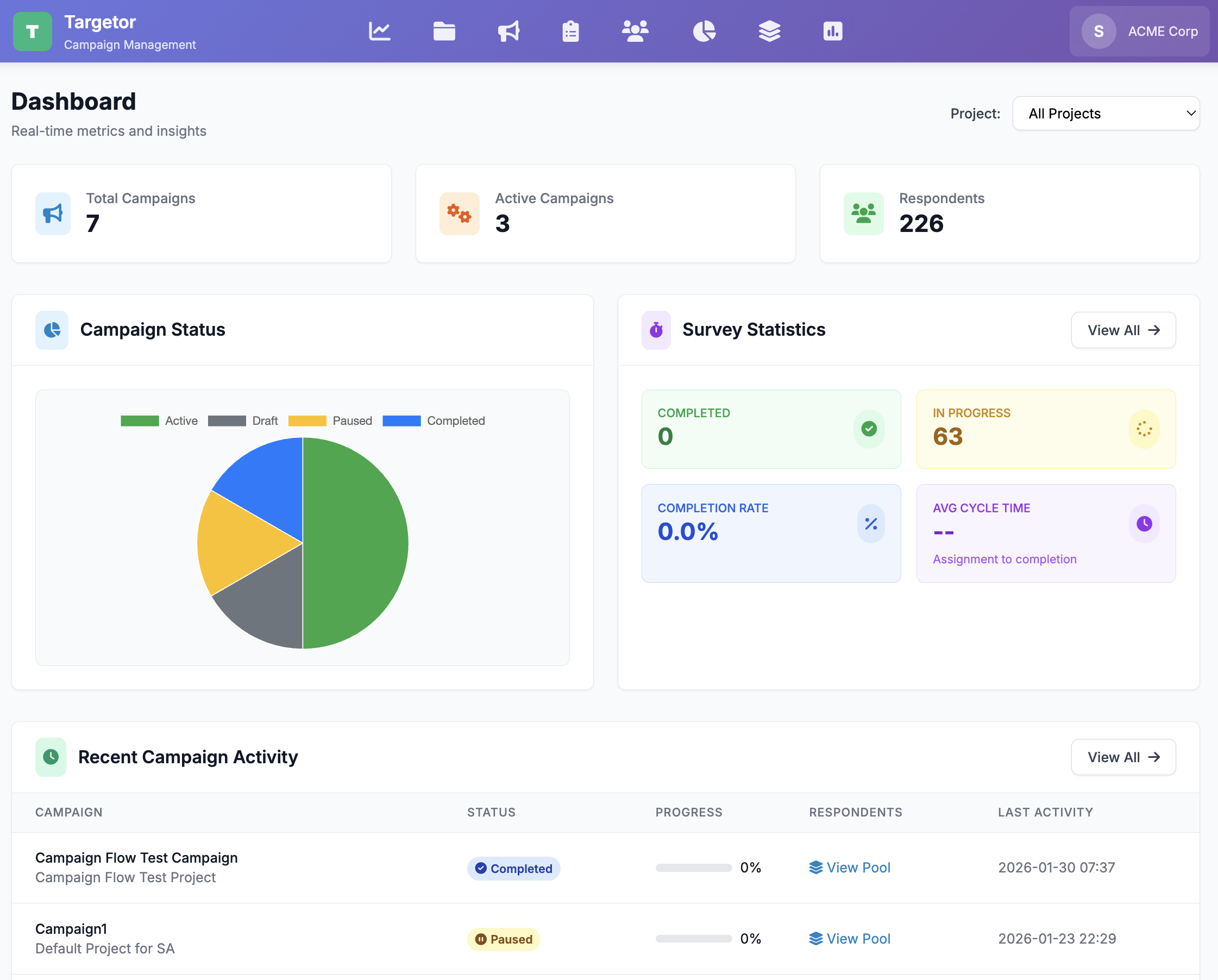
Campaign
Target the right audience with AI-powered sampling strategies and demographic distribution.
SirWay
Execute
Execute surveys via magic links, interviewer-assisted interviews (phone & in-person), or AI simulation with persona profiles.
Balansor
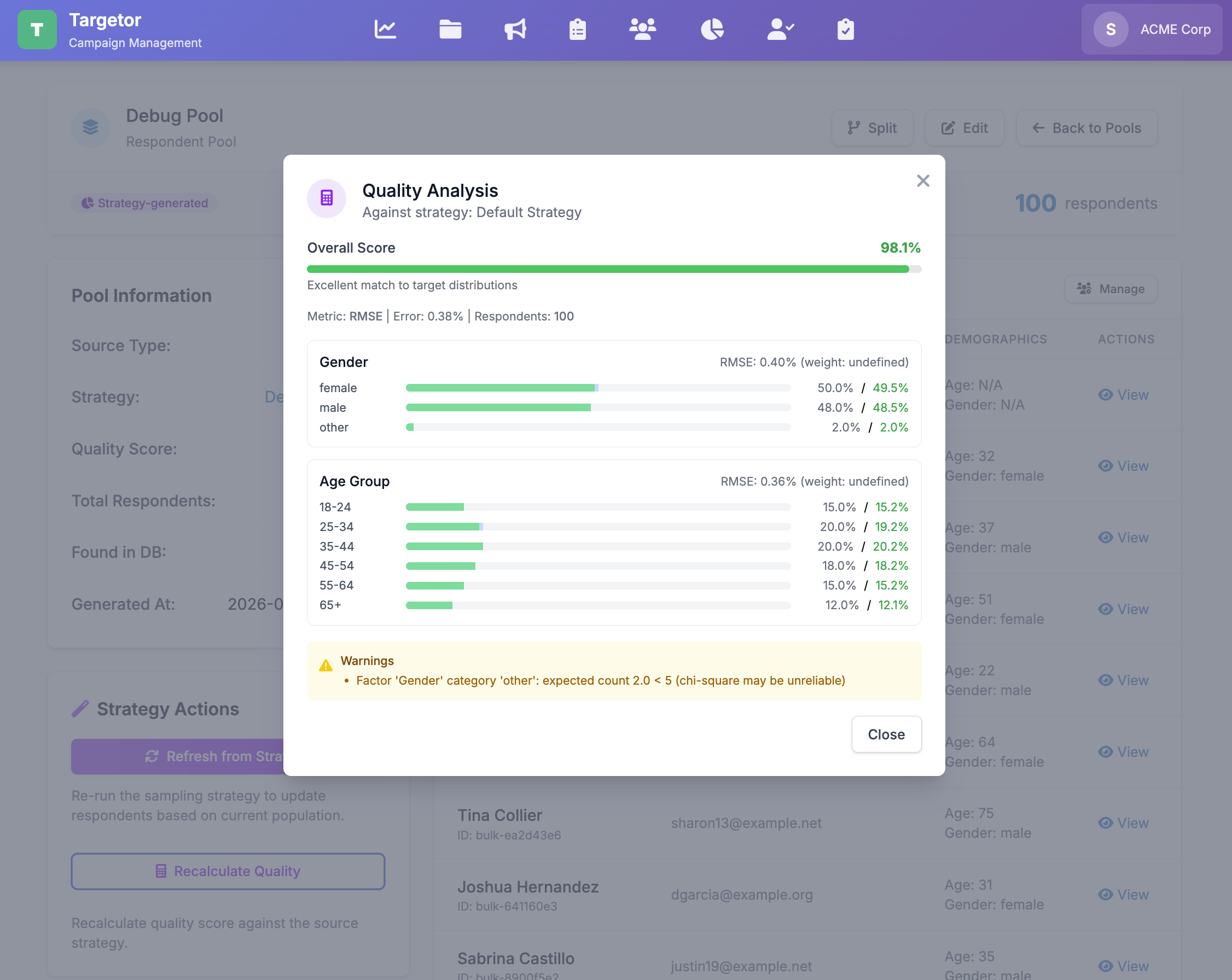
Data Quality Analysis
Weight, measure, and defend your dataset — raking, representativeness metrics, straightlining and speeder flags, multi-format export.